概述
许多科学数据集并非随机缺失若干条目,而是通过传感器、卫星、探针或仿真,只揭示底层场的结构化子区域。困难在于,标准监督模型需要「不完整输入—完整目标」配对,而在此设定下训练阶段从未出现完整目标。
关键思路是在每条部分观测内部构造监督:从已观测区域中,将一部分隐藏为 query 目标,另一部分作为 context 输入。若划分规则设计得当,模型会反复学习如何用已观测片段预测被遮蔽片段,这种局部自监督可迁移到测试时真正未观测的区域。
本页总结围绕该思路的两项关联工作。第一项探讨在观测掩码具有已知结构时,手工设计的划分能走多远。第二项用可学习的掩码生成先验替代手工规则,使同一原理能处理复杂的空间缺失模式。
技术路线图
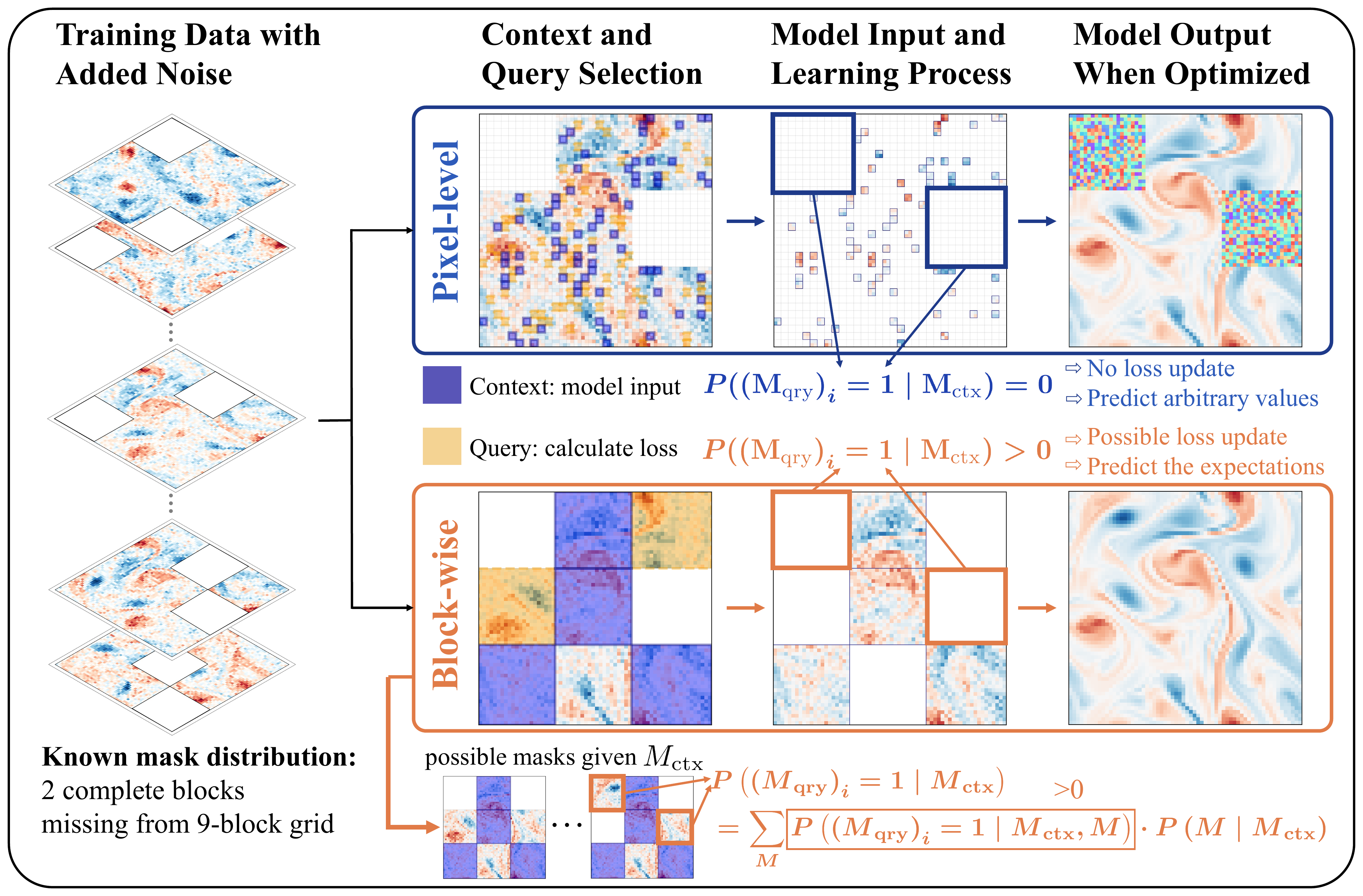
上图将共享学习原理与两种掩码构造方式分开。两项工作使用相同的 context-query 去噪骨干,主要区别在于如何选择 context/query 划分,使没有可恢复维度被遗漏在训练信号之外。
阶段 1 · 骨干
给定部分观测 \(u_{\text{obs}} = M \odot u_0\) 与掩码 \(M\),将观测支撑划分为 context \(M_{\text{ctx}}\)(输入)与 query \(M_{\text{qry}}\)(损失)。仅依据 context 训练扩散去噪器 \(u_\phi\)。
阶段 2a · 工作 I
以与 \(p_{\text{mask}}(M)\) 相同结构采样 \(M_{\text{ctx}}\),使每个已观测维度都能以正概率被 query。推理时集成多个 context 掩码。
阶段 2b · 工作 II
在 \(p(M)\) 上预训练 BFN,令 \(M_{\text{ctx}} = M_1 \odot M_2\)(两次独立掩码)。交集保证严格正性;观测对齐引导锚定生成。
1. 问题设定
完整数据 \(u_0 \in \mathbb{R}^d \sim p_{\text{data}}\),二值观测掩码 \(M \in \{0,1\}^d \sim p_{\text{mask}}(M)\),且 \(p_{\text{mask}}(M \mid u_0) = p_{\text{mask}}(M)\)。我们仅观测
\[u_{\text{obs}} = M \odot u_0\]训练中从未出现完整样本。目标:学习 \(p_\phi(u_0 \mid u_{\text{obs}}, M)\)。
直观上,\(M\) 标明哪些坐标可见,\(1-M\) 标记最终要重建的区域。挑战不仅是填补特定缺失区域,而是从每条样本以不同结构化方式被审查的数据集中,学习完整场的条件分布。
2. 统一的 Context-Query 骨干
骨干将每条部分观测视为一个小型自监督任务。模型不直接重建从未观测的条目,而是先重建「已观测但被故意从输入中隐藏」的条目。这样既提供有效训练目标,又使测试时任务与插补对齐。
层次化掩码
将 \(u_{\text{obs}}\) 视为「在其支撑内完整」,再划分为 context 掩码 \(M_{\text{ctx}} \subseteq M\)(模型输入)与 query 掩码 \(M_{\text{qry}} \subseteq M\)(损失区域)。带噪状态为
\[u_{\text{obs},t} = M \odot (\alpha_t u_{\text{obs}} + \sigma_t \epsilon),\]训练 \(u_\phi\) 仅依据 context 预测干净数据:
\[\mathcal{L}(t, u_{\text{obs}}, M_{\text{ctx}}, M_{\text{qry}}) = \big\| M_{\text{qry}} \odot \big( u_\phi(t,\, M_{\text{ctx}} \odot u_{\text{obs},t},\, M_{\text{ctx}}) - u_{\text{obs}} \big) \big\|^2\]模型只看到 \(M_{\text{ctx}}\) 与掩码输入——它必须推断被遮蔽区域,而非记忆。
核心结论
主要保证很直接:模型只能学到有时出现在 query 集中的维度。若某坐标在固定 context 下始终不参与损失,目标函数不会驱使去噪器在该处正确。
最小化损失后,对每个维度 \(i\) 有
\[\big(u_\phi(t, M_{\text{ctx}} \odot u_{\text{obs},t}, M_{\text{ctx}})\big)_i = \begin{cases} \mathbb{E}\!\left[(u_0)_i \mid M_{\text{ctx}} \odot u_{\text{obs},t},\, M_{\text{ctx}}\right], & P((M_{\text{qry}})_i = 1 \mid M_{\text{ctx}}) > 0 \\[4pt] \text{任意}, & P((M_{\text{qry}})_i = 1 \mid M_{\text{ctx}}) = 0 \end{cases}\]若所有可能的 \(M_{\text{qry}}\) 的并集覆盖全部维度,则
\[u_\phi = \mathbb{E}[u_0 \mid M_{\text{ctx}} \odot u_{\text{obs},t}, M_{\text{ctx}}].\]维度 \(i\) 的期望平方梯度与参数更新频率均与 \(p_i := P((M_{\text{qry}})_i = 1 \mid M_{\text{ctx}})\) 同阶——零 query 维度根本得不到梯度。
设计原则
整个框架归结为一项要求(外加平衡条件):
\[P((M_{\text{qry}})_i = 1 \mid M_{\text{ctx}}) > 0 \quad \forall\, i:\ (M_{\text{ctx}})_i = 0, \qquad P((M_{\text{qry}})_i = 1 \mid M_{\text{ctx}}) \approx P((M_{\text{qry}})_j = 1 \mid M_{\text{ctx}})\]下面两项工作是对「如何保证严格正性?」的两种回答——一种启发式,一种生成式。
3. 工作 I — 分布保持划分
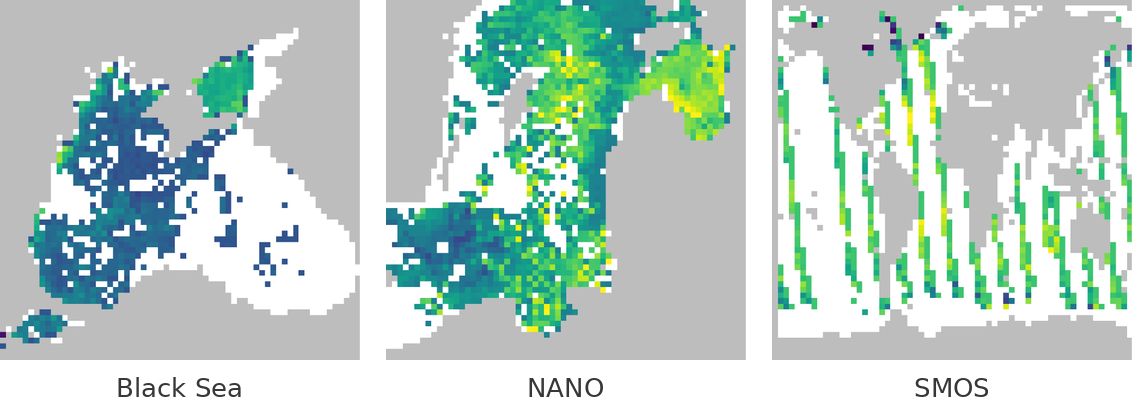
工作 I 适用于观测掩码具有已知结构的实用路线,如独立像素 dropout、规则传感器模式或块状遮挡。无需学习单独的掩码生成器,而是将 context 掩码设计为遵循与原始观测过程相同的模式族。
划分
由全概率公式分解 query 概率:
\[P((M_{\text{qry}})_i = 1 \mid M_{\text{ctx}}) = \sum_{M} P((M_{\text{qry}})_i = 1 \mid M_{\text{ctx}}, M)\, P(M \mid M_{\text{ctx}})\]由于 \(M_{\text{ctx}} \subseteq M\),以与 \(p_{\text{mask}}(M)\) 相同的结构模式采样 \(M_{\text{ctx}}\)(独立像素 → 独立丢弃像素;块状结构 → 丢弃整块),使多个 \(M\) 与给定 \(M_{\text{ctx}}\) 相容,两因子可同时为正 → 每个已观测维度的正性成立。
Context 过少 → 信息缺口大、方差高、收敛慢;过多 → \(p_i\) 极小、更新稀少。中等比例最优。
集成推理
训练时去噪器只看到 context 子集;推理时则有完整观测支撑 \(M\)。集成让模型回答多个略有不同的 context 问题并平均答案,在不改变已训练骨干的前提下利用额外观测。
推理存在训练/测试不匹配:模型给出 \(\mathbb{E}[u_0 \mid M_{\text{ctx}} \odot u_{\text{obs},t}, M_{\text{ctx}}]\),而我们想要 \(\mathbb{E}[u_0 \mid u_{\text{obs},t}, M]\)。通过对 context 掩码集成来桥接。
单步采样。 施加极小噪声 \(u_\delta = \alpha_\delta u_{\text{obs}} + \sigma_\delta \epsilon\),\(0 < \delta \ll 1\)(使 \(M \odot u_\delta \approx u_{\text{obs}}\)),再对 \(K\) 个 context 掩码取平均:
\[\hat\mu_K = \frac{1}{K} \sum_{k=1}^{K} u_\phi\!\left(\delta,\, M_{\text{ctx}}^{(k)} \odot u_{\text{obs},\delta},\, M_{\text{ctx}}^{(k)}\right) \approx \mathbb{E}[u_0 \mid u_{\text{obs}}, M]\]为何有效。 设 \(u_\phi(t, \text{ctx}) = \mathbb{E}[u_0 \mid \text{ctx}] + b(\text{ctx}) + \epsilon_{\text{bias}}(\text{ctx})\),\(\hat\mu_K = \frac{1}{K} \sum_k u_\phi(t, \text{ctx}^{(k)})\):
\[\mathbb{E}\big[\|\hat\mu_K - \mathbb{E}[u_0 \mid \text{obs}]\|^2\big] = \big\|\underbrace{\mathbb{E}[\mathbb{E}[u_0 \mid \text{ctx}]] - \mathbb{E}[u_0 \mid \text{obs}]}_{\text{信息缺口}} + \underbrace{\mathbb{E}[b(\text{ctx})]}_{\text{模型偏差}}\big\|^2 + \frac{1}{K}\big(\underbrace{\mathrm{Var}[\mathbb{E}[u_0 \mid \text{ctx}]]}_{\text{数据方差}} + \underbrace{\mathrm{Var}[b(\text{ctx})] + \mathrm{Var}[\epsilon_{\text{bias}}]}_{\text{模型方差}}\big)\] \[\lim_{K \to \infty} \mathbb{E}\big[\|\hat\mu_K - \mathbb{E}[u_0 \mid \text{obs}]\|^2\big] = \big\|\mathbb{E}[\mathbb{E}[u_0 \mid \text{ctx}]] - \mathbb{E}[u_0 \mid \text{obs}] + \mathbb{E}[b(\text{ctx})]\big\|^2\]平均消去所有方差项;残余误差仅为信息缺口与系统偏差。
多步采样。 当后验非近确定性时,将每步去噪的去噪器替换为两个集成估计的加权组合:
\[\hat u_\phi(t, u_t, u_{\text{obs}}, M) \approx \omega_t\, \mathbb{E}[u_0 \mid u_t] + (1 - \omega_t)\, \mathbb{E}[u_0 \mid u_{\text{obs}}, M]\]其中 \(\omega_t\) 单调递增 \(0 \to 1\)。两个条件期望用对称蒙特卡洛集成估计:
\[\mathbb{E}[u_0 \mid u_t] \approx \frac{1}{K} \sum_{k=1}^{K} u_\phi\!\left(t,\, M_{\text{rnd}}^{(k)} \odot u_t,\, M_{\text{rnd}}^{(k)}\right), \qquad \mathbb{E}[u_0 \mid u_{\text{obs}}, M] \approx \frac{1}{K} \sum_{k=1}^{K} u_\phi\!\left(\delta,\, M_{\text{ctx}}^{(k)} \odot u_{\text{obs},\delta},\, M_{\text{ctx}}^{(k)}\right)\]其中 \(M_{\text{rnd}}^{(k)}\) 为服从与 \(M_{\text{ctx}}\) 相同边缘分布的随机掩码(不必 \(\subseteq M\)),\(M_{\text{ctx}}^{(k)} \subseteq M\)。采样遵循 RePaint 式方案:在未观测条目上用模型估计噪声,在已观测条目上由已知干净值直接计算,再经
\[\epsilon_{\text{full}} = M \odot \epsilon_{\text{obs}} + (1 - M) \odot \epsilon_{\text{unobs}},\]合并后推进扩散 ODE——全程保持观测一致。
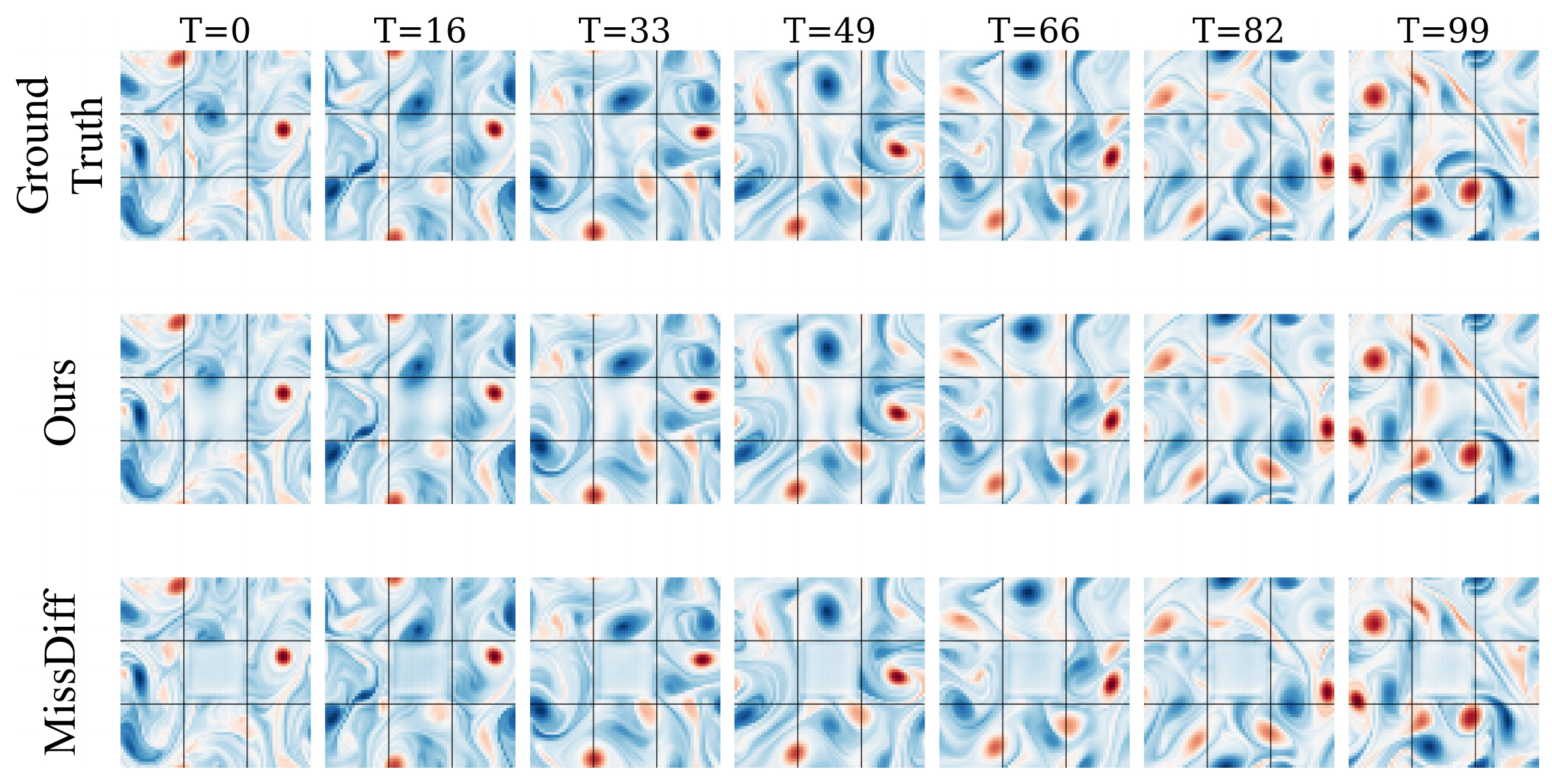
4. 工作 II — 生成式先验划分
工作 II 针对掩码几何过于复杂、难以用少量手写规则指定的更难情形。不手工决定合法 context 划分的外观,而是先学习观测掩码分布,再从该先验采样划分。
动机
分布保持规则须针对每种观测模式手工设计(像素 dropout、块遮挡等),引入模式相关超参,且难以在复杂真实空间依赖下普遍保证正性。目标:对任意空间拓扑均有效的单一机制。
交集免费获得正性
用生成先验建模真实掩码分布 \(p(M)\);抽取两个独立同分布掩码 \(M_1, M_2 \sim p(M)\) 并令
\[M_{\text{ctx}} = M_1 \odot M_2, \qquad M_{\text{qry}} = M_1 \odot (1 - M_{\text{ctx}})\]定理(经交集的严格正性): 对任意合法 \(M_{\text{ctx}} = m\) 与任意 \(m_i = 0\) 的 \(i\),
\[P((M_{\text{qry}})_i = 1 \mid M_{\text{ctx}} = m) > 0.\]这消除所有启发式设计——但现需对离散 \(p(M)\) 采样。
用 BFN 建模 p(M)
我们需要对高维离散掩码先验 \(p(M)\) 的模型,且采样时支持潜空间梯度干预。本工作中 BFN 通过将二值类别提升到连续 logits、用离散数据匹配训练、并在高斯前向动力学下经 Tweedie 导出 score 采样,恰好提供该桥梁。
具体实现采用标准离散 BFN 配方(scaled-logit 提升、\(\mathcal{L}_{\mathrm{DM}}\) 与概率流采样):
\[\nabla_{x_t}\log p_t(x_t)\propto \alpha_t K \hat{e}_{\theta} - x_t.\]完整数学处理见专文:平移不变连续扩散视角下的贝叶斯流网络。
观测对齐条件化
纯从掩码先验采样可能生成结构合理但与当前观测对齐不佳的 context。引导项将生成掩码拉向实际可见区域,同时保留足够随机性以维持 query 覆盖为正。
无条件交集可能与真实 \(M\) 重叠过少 → context 过稀。通过分类器引导将生成锚定到实际观测:
随机锚点。 \(y_i = \mathbf{1}[r_i < \rho] \cdot M_i\),\(r_i \sim \mathrm{Uniform}(0,1)\)——随机保留观测点比例 \(\rho\) 注入多样性(完全锚定会坍缩为单一确定性掩码)。
全局归一化引导损失。
\[\mathcal{L}_{\text{guidance}}(x_t, y) = -\frac{1}{d} \sum_{i=1}^d \big[ y_i \log \hat e_i + (1 - y_i) \log(1 - \hat e_i) \big]\]全局归一化在不同稀疏度下稳定梯度。
潜空间干预。
\[x_{t_{i+1}} \leftarrow x_{t_{i+1}}^{\text{base}} - w_g \nabla_{x_{t_i}} \mathcal{L}_{\text{guidance}}(x_{t_i}, y)\]定理(引导下正性保持): 在比例引导交集约束下,对任意已观测维度 \(i\)(\(M_i = 1\)),\(P((M_{\text{qry}})_i = 1 \mid C_k) > 0\)——条件化不破坏保证。
训练
与骨干相同的 context-query 目标,配合生成的划分:
\[M_{\text{ctx}} = \hat M \odot M, \quad M_{\text{qry}} = M \odot (1 - M_{\text{ctx}}), \qquad \mathcal{L} = \mathbb{E}\big[\| M_{\text{qry}} \odot (u_\phi(M_{\text{ctx}} \odot u_{\text{obs}}, M_{\text{ctx}}) - u_{\text{obs}}) \|^2 \big]\]5. 总结
两项工作围绕同一信息:若自监督 query 机制覆盖每个可恢复坐标,不完整观测可用于学习完整动力学。差别在于覆盖由我们设计的规则实现,还是由学习的掩码分布实现。
| 路线 | 正性保障方式 | 权衡 |
|---|---|---|
| 工作 I(分布保持) | 以与 \(p_{\text{mask}}\) 相同结构采样 \(M_{\text{ctx}}\);推理时集成 | 模式相关启发式;难覆盖复杂空间依赖 |
| 工作 II(生成式先验) | 从 \(p(M)\) 两次独立掩码的交集;观测对齐引导 | 需学习并采样 \(p(M)\),但对任意拓扑成立 |
两条路线互补而非竞争。工作 I 轻量,在 \(p_{\text{mask}}(M)\) 结构已知或可解析时无需额外生成模型;工作 II 适用于掩码结构复杂或未知的情形,按构造对任意拓扑保证正性(工作 I 则依赖匹配采样)。
正性现按构造对每种合法拓扑成立,模型将重建从合成训练掩码迁移到测试时真正缺失的区域——全程从未见过完整场。